
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 현대엔지니어링
- 사회조사분석사2급실기신청꿀팁
- 공모주청약
- 현대엔지니어링 수요예측
- 사회조사분석사 2급 공부방법
- 알고리즘
- 사회조사분석사 2급 접수
- 사회조사분석사 2급
- 너비우선탐색
- 시물레이션
- 오미크론 자가격리
- 사이킷런
- DFS
- 머신러닝
- 사회조사분석사 2급 필기 요약정리
- 2월공모주
- 파이썬 정렬
- 정렬
- 사회조사분석사 2급 독학
- 사회조사분석사 2급 기출문제집
- 벽부수고이동하기 파이썬
- BFS
- 백준 알고리즘
- 사회조사분석사 2급 필기 공부방법
- 그리디
- 사회조사분석사 2급 필기 시험시간
- 백준
- 공모주 청약
- 공모주
- 사회조사분석사2급실기신청
- Today
- Total
세상을 바꾸는 데이터
[Pandas] 판다스 - 데이터 선택 및 필터링 (indexing) 본문
DataFrame에서 데이터를 선택하고 필터링하는 방법에 대해 알아보자.
import numpy as np
import pandas as pd
데이터 선택에서 numpy와 pandas 차이점

넘파이와 DataFrame 간 데이터 선택에서 가장 유의해야 할 부분은 [ ] 연산자이다. 넘파이에서 [ ]연산자는 행의 위치, 열의 위치, 슬라이싱 범위 등을 지정해 데이터를 가져올 수 있었다. 반면 DataFrame 뒤에 있는 [ ] 안에 들어갈 수 있는 것은 칼럼 명 문자(또는 칼럼 명 리스트 객체), 인덱스로 변환 가능한 표현식이다.
titanic_df = pd.read_csv('titanic_train.csv')
print('단일 컬럼 데이터 추출:\n', titanic_df[ 'Pclass' ].head(3))
print('\n여러 컬럼들의 데이터 추출:\n', titanic_df[ ['Survived', 'Pclass'] ].head(3))
[Output]

명칭 기반 인덱싱과 위치 기반 인덱싱의 구분
명칭(Label) 기반 인덱싱은 칼럼의 명칭을 기반으로 위치를 지정하는 방식이다. '칼럼명'과 같이 명칭으로 열 위치를 지정하는 방식이다. DataFrame.loc[ ]를 이용한다.
위치(Position) 기반 인덱싱은 0을 출발점으로 하는 가로축, 세로축 좌표 기반의 행과 열 위치를 기반으로 데이터를 지정한다. 따라서 행, 열 값으로 정수가 입력된다. DataFrame.iloc[ ]를 이용한다.
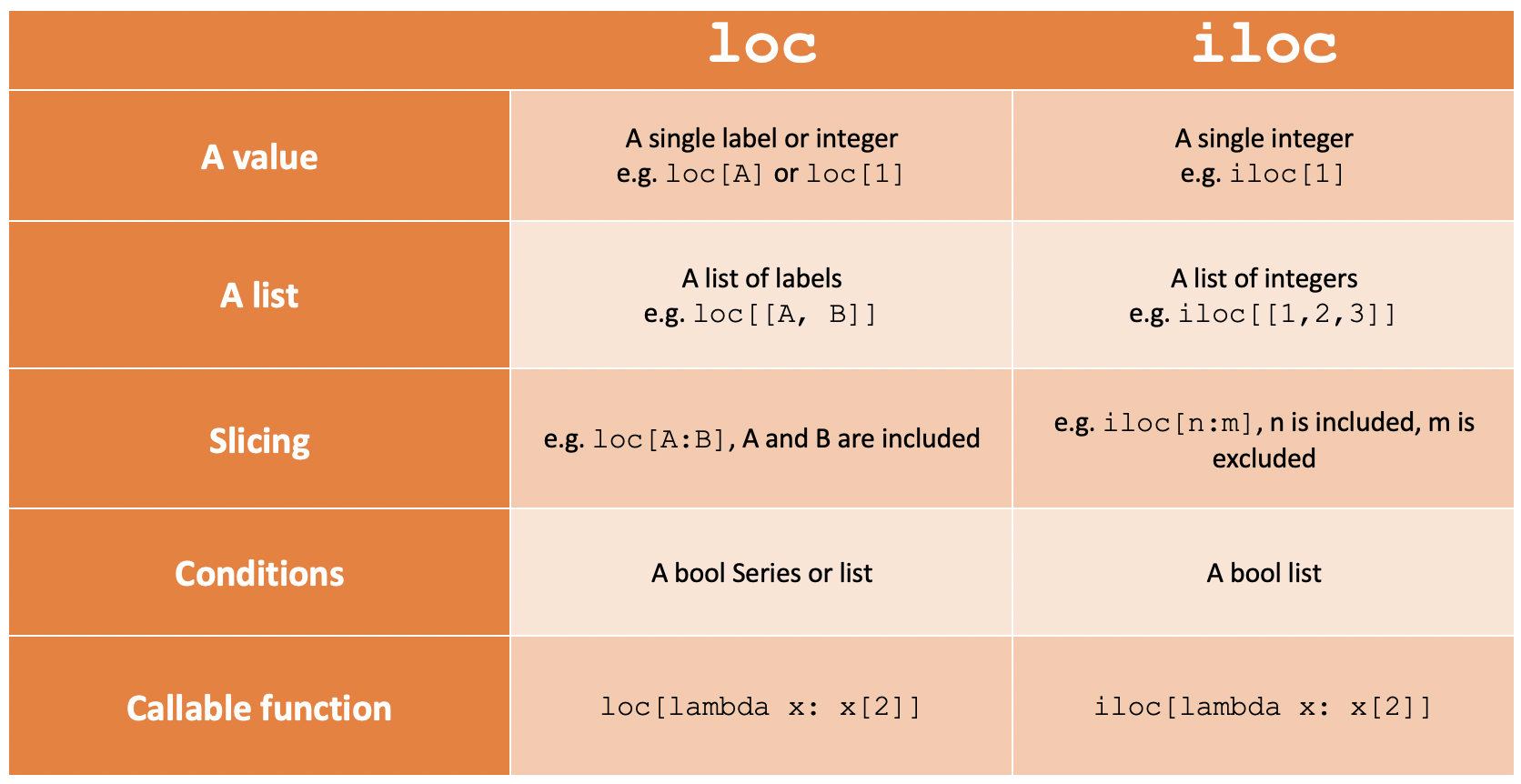
위치 기반 인덱싱 DataFrame iloc[ ] 연산자
titanic_df.head(5) # 타이타닉 데이터 개략적 확인
[Output]

- DataFrame.iloc[ ]
iloc[ ]는 위치 기반 인덱싱만 허용하기 때문에 행과 열 값으로 integer 또는 integer형의 슬라이싱, 팬시 리스트 값, 불린 인덱싱 등을 입력해야 한다. DataFrame인 titanic_df의 첫 번째 행, 첫 번째 열의 데이터를 추출하고자 한다면 다음과 같이 코드를 작성하면 된다.
titanic_df.iloc[0, 0] # PassengerId 칼럼 1행에 있는 1값 출력
다음과 같이 iloc에서 '칼럼 명' 명칭을 이용하면 오류를 발생시킨다.
titanic_df.iloc[0, 'Pclass'] # 오류 발생
titanic_df.iloc['Ticket', 0] # 오류 발생
명칭 기반 인덱싱 DataFrame loc[ ] 연산자
- DataFrame.loc[ ]
loc[ ]는 명칭 기반으로 데이터를 추출한다. 행 위치에는 DataFrame index 값을, 열 위치는 칼럼 명을 입력해준다.
다음은 인덱스 값이 2인 행의 칼럼 명이 'Pclass'인 데이터를 추출한 것이다.
여기서 index가 숫자형일 수도 있기 때문에 명칭 기반이라고 무조건 문자열을 입력하는 것은 아니다.
titanic_df.loc[2, 'Pclass'] # index값이 2인 행의 칼럼 명이 'Pclass'인 데이터 추출
# 결과값: 3
iloc와 loc 차이점 정리
명칭 기반 인덱싱(loc): DataFrame의 인덱스나 칼럼명으로 데이터에 접근하는 것
위치기반 인덱싱(iloc): 0부터 시작하는 행, 열의 위치 좌표에만 의존하는 것
※ 주의 ※
DataFrame의 인덱스가 숫자형일 경우 행 위치에 있는 숫자는 위치 기반 인덱싱이 아니라 명칭 기반 인덱싱의 DataFrame 인덱스를 가리킨다.
불린 인덱싱
불린 인덱싱은 명칭 or 위치 기반 인덱싱과 상관없이 조건식을 [ ] 안에 기입하여 필터링을 수행할 수 있는 매우 편리한 데이터 필터링 방식이다. 불린 인덱싱은 [ ], loc[ ]에서 공통으로 지원하지만 iloc[ ]는 정수형 값이 아닌 불린 값에 대해서는 지원하지 않는다.
다음은 titanic호 탑승자 중 나이가 10살 미만인 데이터를 추출하는 방법이다.
titanic_df = pd.read_csv('titanic_train.csv')
titanic_boolean = titanic_df[titanic_df['Age'] < 10]
print(titanic_boolean)
[Output]

- 원하는 칼럼 명만 별도로 추출하기
다음은 10세 미만인 승객의 나이와 이름 칼럼만 추출한다.
titanic_df_age = titanic_df[titanic_df['Age']< 10][['Name', 'Age']].head(3)
print(titanic_df_age)
[Output]
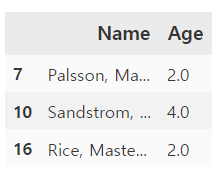
- 여러 개의 조건식을 이용해 데이터 추출하기
생존자이면서 선실등급이 3등급이고, 나이가 20살 미만이며 성별이 여성인 승객의 Name과 Ticket 칼럼명만 별도로 추출해보자.
조건 1 : Survived = 1
조건 2: Pclass = 3
조건 3: Age < 20
조건 4: Sex = 'female'
titanic_select = titanic_df[(titanic_df['Survived'] == 1) & (titanic_df['Pclass'] == 3) &
(titanic_df['Age'] < 20) & (titanic_df['Sex'] == 'female')][['Name', 'Ticket']]
print(titanic_select)
[Output]
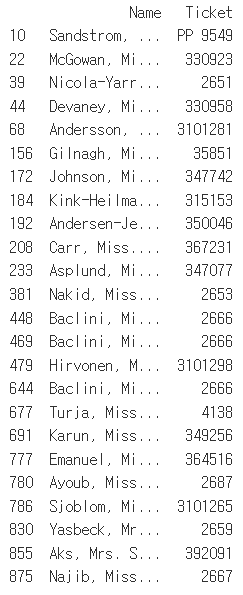

Reference
https://www.thedataincubator.com/blog/2018/02/21/numpy-and-pandas/
https://towardsdatascience.com/how-to-use-loc-and-iloc-for-selecting-data-in-pandas-bd09cb4c3d79
https://github.com/chulminkw/PerfectGuide
'ML > Pandas' 카테고리의 다른 글
| [Pandas] 판다스 - 결손 데이터 처리하기 (8) | 2022.01.26 |
|---|---|
| [Pandas] 판다스 - DataFrame을 정렬, 집계, 그룹하는 방법 (2) | 2022.01.25 |
| [Pandas] 판다스 - DataFrame 칼럼 데이터 생성, 수정, 삭제 (10) | 2022.01.23 |
| [Pandas] 판다스 - 데이터프레임과 넘파이 상호 변환 (0) | 2022.01.23 |
| [Pandas] 판다스 - 파일을 DataFrame으로 불러오기, 기본 API (2) | 2022.01.19 |



